
Following on from an Introduction to Neural Networks and Regularization for Neural Networks, this post provides an implementation of a general feedforward neural network program in Python. Writing the code taught me a lot about neural networks and it was inspired by Michael Nielsen’s fantastic book Neural Networks and Deep Learning.
Whilst reasonably short, and containing no error checking, the program is quite powerful. The network can be of an arbitrary size and it is a vectorized implementation, which significantly speeds up the network computation. That is, batches of data are processed through the network in one pass. The input data is a 2D matrix, in which each row corresponds to an example and each column corresponds to a feature. The output is also a 2D matrix, in which each row corresponds to an example and each column corresponds to an output.
Four activation functions are available: the Sigmoid, ReLU, LeakyReLU and Softmax. It is possible to specify a different activation function for the hidden and output layers. Three cost functions are available: Quadratic, Cross Entropy, and Log Likelihood, and three different parameter initializers. The network is trained using Stochastic Gradient Descent and a user has the freedom to specify the learning rate, batch size and degree of L2 regularization through the lmda parameter. This program also shows how modular neural networks are, and makes it easy to add additional activation, cost, or parameter initialization functions.
The most important parts of the program are included below with an explanation of the main steps. It assumes an intermediate understanding of Python and Object-Oriented Programming. The full code is available here.
Part 2 of this post will give some examples of this program applied to solve two typical prediction problems. The first is a very simple three layer neural network used to solve a two class classification problem. The second are some example network structures and hyper-parameter settings applied to the classic MNIST computer vision task.
If you really want to understand neural networks, I highly recommend building your own. This program is intended as a reference to help readers do so, and to provide guidance when stuck. My next post will include tips for writing your own program as well as some suggested tests, and associated code, to run as you go.
Setup: Building the architecture of the neural network and initializing the variables
class NeuralNet:
def __init__(self, size, costfn=QuadraticCost,
activationfnHidden=SigmoidActivation,
activationfnLast=SigmoidActivation):
self.weights = []
for a, b in zip(size[:-1], size[1:]):
self.weights.append(np.zeros((a,b)))
self.biases = []
for b in size[1:]:
self.biases.append(np.zeros((1, b)))
self.layers = len(size)
self.costfn = costfn
self.activationfnHidden = activationfnHidden
self.activationfnLast = activationfnLast
def initialize_variables(self):
np.random.seed(1)
i = 0
for w in self.weights:
self.weights[i] = Matrix((np.random.uniform(-1, 1,
size=w.shape) / np.sqrt(w.shape[0])))
i += 1
i = 0
for b in self.biases:
self.biases[i] = Matrix(np.random.uniform(-1, 1,
size=b.shape))
i += 1
class Matrix:
def __init__(self, matrix):
self.matrix = matrix
def __mul__(self, other):
return Matrix(np.dot(self.matrix, other.matrix))
def __add__(self, other):
return Matrix(self.matrix + other.matrix)
def __radd__(self, other):
return Matrix(self.matrix + other.matrix)
The first task is to build the network structure. size is a list containing the size of each layer, in order. So, size=(10, 5, 2) is a three layer neural network with one input layer containing 10 nodes, one hidden layer containing 5 nodes and one output layer containing 2 nodes. This information is used to create the weight matrices and bias vectors. The size of the n-th weight matrix is m x r, where m is the number of edges in the n-1 layer and r is the number of edges in the n-th layer. The number of weight matrices is therefore one fewer than the number of layers. Input nodes do not have biases. Bias vectors for the remaining layers have the same number of elements as nodes in a layer.
The rest of the initialization is straightforward. The attributes of the instance of the Neural Net class are set to the specified cost function, hidden layer(s) activation function (activationfnHidden) and output layer activation function (activationfnLast). The default settings are the quadratic cost function and sigmoid activation function for the hidden and output layers. Finally initialize_variables(self) initializes the weights and biases drawn from a uniform distribution centered around 0. Let w be any weight in the network, and b be any bias, and let m be the number of inputs to nodes in the layer that w is associated with. Then we have,
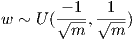
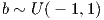
The Matrix class is a helper class intended to make the feedforward function easier to read. It was also a personal exercise in operator overloading and is not essential to the implementation. On reflection it wasn’t as useful as I had hoped due to the need to transpose matrices and apply element wise operations. I have left it in but the implementation would be significantly improved if suitable operators were overloaded to perform transpose and element wise multiplication. It would also make the the use of the Matrix class cleaner, reducing the need to switch between numpy arrays and instances of the class.
Activation Function
class SigmoidActivation:
@staticmethod
def fn(x):
'''Assumes x is an instance of the Matrix class'''
return 1 / (1 + np.exp(-x.matrix))
@staticmethod
def prime(x):
'''Assumes x is an instance of the Matrix class
Derivative of the sigmoid function'''
return np.multiply(SigmoidActivation.fn(x),
(1 - SigmoidActivation.fn(x)))
The SigmoidActivation class is self explanatory, and implements the following two functions;
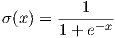

The advantage of structuring the activation function in this way is that it makes it easy to add other activation functions to the program as you can see in the full code. All that is required is that they are implemented as a class with two static methods; fn(x) which computes the activation function given input x, and prime(x) which computes the derivative of the activation function evaluated at x. An activation function class should assume that x is an instance of the Matrix class and ensure that operations are applied element-wise.
Feedforward
def feedforward(self, data):
z = Matrix(data)
for w, b in zip(self.weights[0:-1], self.biases[0:-1]):
z = Matrix(self.activationfnHidden.fn(z * w + b))
z = Matrix(self.activationfnLast.fn(z *
self.weights[-1] + self.biases[-1]))
return z.matrix
This function computes one pass of the data through the network. This setup supports batch inputs of any size. data is a 2D matrix, examples x features. The one idiosyncrasy of this implementation vs. others is that the computations for the last layer are outside the loop. This allows for a different activation function in the last layer should a user wish to implement this.
Loss (cost) function
class QuadraticCost:
cost_type = "QuadraticCost"
@staticmethod
def compute_cost(output, y, lmda, weights):
'''Cost function cost'''
num_data_points = output.shape[0]
diff = y - output
'''Regularization cost'''
sum_weights = 0
for w in weights:
sum_weights +=
np.sum(np.multiply(w.matrix,w.matrix))
regularization = (lmda * sum_weights)
/ (num_data_points * 2)
return np.sum(np.multiply(diff, diff))
/ (2 * num_data_points) + regularization
@staticmethod
def cost_prime(output, y):
'''Derivative of the quadratic cost function'''
return output - y
The first function compute_cost(output, y, lmda, weights) has two parts. The first part is the cost driven by the accuracy of the network when measured on the training data, i.e. the sum of the squared difference between output and y. The second part is a penalty for large weights. This particular implementation is known as L2 weight regularization and has the effect of shrinking the weights, making the output less sensitive to small perturbations in the input. In practice it helps to prevent the neural network from learning particularities of the training data and achieve better results on unseen data. For an explanation of why neural networks are regularized and an overview of different techniques available to network designers, see this post.
Let W be the set of weight matrices, and N be the number of datapoints. output and y are 2D matrices. Then putting these two parts together, the function that compute_cost(output, y, lmda, weights) implements is;
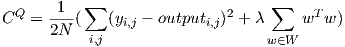
λ controls the extent of the regularization. λ = 0 corresponds to no regularization and λ = 1 corresponds to relatively strong regularization through a large additional penalty on the cost function.
cost_prime(output, y) computes the derivative of the cost function with respect to the output. The derivative of the regularization component of the cost function with respect to a weight matrix, w, is simply w. Since L2 regularization is used throughout this implementation regardless of the cost function, and to avoid cost prime returning a complicated list of partial derivatives, λw is subtracted from the current values of the weights when all of the parameters are updated in the update weights function.
Useful functions: Network predictions in a one hot encoded format and network accuracy for reporting
def predict(self, x):
output = self.feedforward(x)
if (output.shape[1]==1):
'''If only one output, convert to 1
if value > 0.5'''
low_indices = output <= 0.5
high_indices = output > 0.5
output[low_indices] = 0
output[high_indices] = 1
else:
'''Otherwise set maximum valued output
element to 1, the rest to 0'''
max_elem = output.max(axis=1)
max_elem =
np.reshape(max_elem, (max_elem.shape[0], 1))
output = np.floor(output/ max_elem)
return output
def accuracy(self, x, y):
prediction = self.predict(x)
num_data_points = x.shape[0]
if (prediction.shape[1]==1):
result = np.sum(prediction==y) / num_data_points
else:
result =
np.sum(prediction.argmax(axis=1)==y.argmax(axis=1))
/ num_data_points
return result
Predict converts the output nodes of a neural network to 1 if an example belongs to the class corresponding to that node, 0 otherwise. If there is only one output node then an output value >0.5 corresponds to that examples being a member of the positive class, otherwise it is a member of the negative class. If there are more than one output node then the node with the highest output value is converted to a 1 and the rest are set to 0.
Accuracy compares the network prediction to the correct results and returns the percentage of correctly classified examples.
Backpropagation
def backprop(self, x, y, lmda):
num_data_points = x.shape[0]
z_vals = []
a_vals = [x]
''' Feedforward: storing all z and a values
per layer '''
activation = Matrix(x)
for w, b in zip(self.weights[0:-1], self.biases[0:-1]):
z = activation * w + b
z_vals.append(z.matrix)
activation = Matrix(self.activationfnHidden.fn(z))
a_vals.append(activation.matrix)
z = activation * self.weights[-1] + self.biases[-1]
z_vals.append(z.matrix)
activation = Matrix(self.activationfnLast.fn(z))
a_vals.append(activation.matrix)
cost = self.costfn.compute_cost(a_vals[-1], y,
lmda, self.weights)
cost_prime = self.costfn.cost_prime(a_vals[-1], y)
''' Backprop: Errors per neuron calculated first
starting at the last layer and working backwards
through the network, then partial derivatives
are calculated for each set of weights and biases
deltas = neuron error per layer'''
deltas = []
if (self.costfn.cost_type=="QuadraticCost"):
output_layer_delta = cost_prime *
self.activationfnLast.prime(Matrix(z_vals[-1]))
elif (self.costfn.cost_type=="CrossEntropyCost"):
output_layer_delta = cost_prime
else:
print("No such cost function")
exit(1)
deltas.insert(0, output_layer_delta)
for i in range(1,self.layers-1):
interim = np.dot(deltas[0],
(np.transpose(self.weights[-i].matrix)))
act_prime =
self.activationfnHidden.prime(Matrix(z_vals[-i-1]))
delta = np.multiply(interim, act_prime)
deltas.insert(0, delta)
nabla_b = []
for i in range(len(deltas)):
interim = np.sum(deltas[i], axis=0)
/ num_data_points
nabla_b.append(np.reshape(interim,
(1, interim.shape[0])))
nabla_w = []
for i in range(0,self.layers-1):
interim = np.dot(np.transpose(a_vals[i]),
deltas[i])
interim = interim / num_data_points
nabla_w.append(interim)
return cost, nabla_b, nabla_w
The optimal parameter values in a neural network are found through the gradient descent. This is how a network learns. In each iteration of training, the neural network produces output via the feedforward function, computes the associated cost and calculates the partial derivatives of the cost function with respect to each of the parameter values. These values are then used to update the parameters, resulting in a small step in the direction of steepest gradient towards a lower cost. Backpropagation is the algorithm used to efficiently find the values of the partial derivatives and is an elegant application of dynamic programming and the chain rule of calculus.
Michael Nielsen’s explanation of backpropagation is superb, so I will not attempt to replicate it here. There are three steps to the algorithm:
- Calculate the error of each node, defined as the partial derivative of the cost with respect to the output of each node, before the activation function is applied
- Calculate the partial derivative of the cost with respect to the biases
- Calculate the partial derivative of the cost with respect to the weights
The terminology below is Michael Nielsen’s, see his chapter on backpropagation for more details (link above). Let’s define the error of the nodes in the output layer as δL, and the error of nodes in any other layer as δl. Define the output of nodes in a layer before the activation function is applied as zl, zL for the output layer. Finally, define the output of nodes in a layer after the activation function is applied as al, aL for the output layer. Finally, suppose there are n output nodes and define ∇a C as the vector of the partial derivatives of the cost function with respect to aL, that is
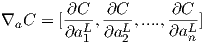
Let the derivative of the cost function be, σ'(x), ⊙ is the element wise multiplication operator, and wl is the weight matrix for layer l. Then the equation to calculate the error for each node is;
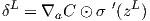
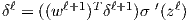
The errors are propagated backwards through the network from the output layer downwards. Errors are pushed down a layer by being multiplied with the relevant weights in the same layer and then the dot product is taken of the result and the derivative of the activation function in the layer below, evaluated at the input value to that function, zl. From here it is easy to calculate the relevant partial derivatives for the weights and biases.
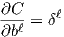
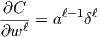
The first part of the backpropagation function calculates and stores all of the z and a values. Then δL (output layer delta) is calculated first, then the rest of the layers in a loop. Finally the partial derivatives with respect to the weights (nabla_w) and biases (nabla_b) are calculated and returned.
Parameter updates
def update_weights(self, nabla_w, nabla_b,
learning_rate, lmda, num_data_points):
i = 0
weight_mult = 1 - ((learning_rate * lmda)
/ num_data_points)
for w, nw in zip(self.weights, nabla_w):
self.weights[i].matrix = weight_mult * w.matrix
- learning_rate * nw
i += 1
i = 0
for b, nb in zip(self.biases, nabla_b):
self.biases[i].matrix = b.matrix
- learning_rate * nb
i += 1
This is a fairly self explanatory function. It controls the updates to the weights and biases. The biases update is straightforward, depending only on the values of the current weights, learning rate and gradients (nabla_b). The weight updates are a little more complex since they also includes the regularization component. Let λ be the variable lmda, α be the learning rate, and n be the number of data points. Then the function it computes is
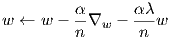
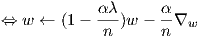
Note: nabla_w and nabla_b have already been divided by the number of data points in the backpropagation function so there is no need to do so in this function.
Stochastic Gradient Descent
def SGD(self, x, y, valid_x, valid_y, learning_rate, epochs,
reporting_rate, lmda=0, batch_size=10, verbose=False):
training_cost = []
valid_cost = []
num_data_points = batch_size
total_data_points = x.shape[0]
output = self.feedforward(x)
cost = self.costfn.compute_cost(output, y,
lmda, self.weights)
accuracy = self.accuracy(x, y)
valid_accuracy = self.accuracy(valid_x, valid_y)
print("Training cost at start of training is %.5f
and accuracy is %3.2f%%" % (cost, accuracy * 100))
print("Validation set accuracy is %3.2f%%" %
(valid_accuracy * 100))
if (verbose==True):
print("First 10 output values are:")
print(output[0:10,:])
for i in range(epochs):
data = np.hstack((x,y))
input_dims = x.shape[1]
output_dims = y.shape[1]
np.random.shuffle(data)
batches = []
nabla_w =[]
nabla_b = []
for k in range(0, (total_data_points - batch_size),
batch_size):
batch = data[k:(k+batch_size),:]
batches.append(batch)
num_batches = len(batches)
for j in range(num_batches):
batch_x = batches[j][:,:input_dims]
batch_y = batches[j][:,input_dims:]
if (batch_y.ndim == 1):
batch_y = np.reshape(batch_y,
(batch_y.shape[0],1))
cost, nabla_b, nabla_w =
self.backprop(batch_x, batch_y, lmda)
self.update_weights(nabla_w, nabla_b,
learning_rate, lmda, num_data_points)
'''Monitoring progress (or lack of...)'''
training_cost.append(cost)
valid_output = self.feedforward(valid_x)
valid_c = self.costfn.compute_cost(valid_output,
valid_y, lmda, self.weights)
valid_cost.append(valid_c)
if (i % reporting_rate == 0):
output = self.feedforward(x)
cost = self.costfn.compute_cost(output,
y, lmda, self.weights)
accuracy = self.accuracy(x, y)
valid_accuracy = self.accuracy(valid_x, valid_y)
print("Training cost in epoch %d is %.5f and
accuracy is %3.2f%%" % (i, cost,
accuracy * 100))
print("Validation set accuracy is %3.2f%%" %
(valid_accuracy * 100))
if (verbose==True):
print("First 10 output values are:")
print(output[0:10,:])
print("Weight updates")
for i in range(len(self.weights)):
print(nabla_w[i])
print("Bias updates")
for i in range(len(self.biases)):
print(nabla_b[i])
print("Weights")
for i in range(len(self.weights)):
print(self.weights[i].matrix)
print("Biases")
for i in range(len(self.biases)):
print(self.biases[i].matrix)
'''Final results'''
output = self.feedforward(x)
cost = self.costfn.compute_cost(output,y,lmda,self.weights)
prediction = self.predict(x)
accuracy = self.accuracy(x, y)
valid_accuracy = self.accuracy(valid_x, valid_y)
print("Final test cost is %.5f" % cost)
print("Accuracy on training data is %3.2f%%, and
accuracy on validation data is %3.2f%%" %
(accuracy * 100, valid_accuracy * 100))
return training_cost, valid_cost
Stochastic gradient descent puts everything together. After initializing the class and calling one of the variable initializer functions, all you need to do to train the neural network is to call SGD. When SGD returns, the values of the weights and biases will have been updated to the (hopefully) good values that the network found through stochastic gradient descent. Its main role is to create the batches based on the batch size, shuffling the data at the beginning of each epoch, call the backprop and update_weights function on each batch, and report on progress. The verbose parameter controls whether some of the internals of the network are printed out during training. This was mainly useful for debugging the program as I built it and is intended for network of toy sizes (only a few nodes per layer and a few data examples). It helped me to check that the prediction and accuracy functions were correct, that regularization was working as expected, and to pinpoint errors caused by underflow and overflow. It was also interesting to monitor the values of the outputs and weights as very small networks learned.
The SGD function sets all of the hyperparameters:
- x: training data
- y: training labels
- valid_x: validation data
- valid_y: validation labels
- learning_rate: hyperparameter controlling the size of the parameter updates
- epochs: number of complete iterations through the training data
- reporting_rate: how frequently to report the training data cost and accuracy, and validation data accuracy. If epoch % reporting_rate == 0 the results are printed
- lmda: regularization parameter. lmda = 0 corresponds to no regularization
- batch_size: size of the batches used in one feedforward and parameter update step
- verbose: True or False. True prints internal model statistics to the screen.
This code is all you need for a reasonably powerful feedforward neural network. The full program is available here. Not all combinations of cost functions and activation functions in the output layer will work. Different options should be paired as follows:
- Sigmoid + Quadratic
- Sigmoid + Cross Entropy (tends to learn much faster than Sigmoid + Quadratic)
- Softmax + Log Likelihood
ReLU and LeakyReLU should only be used in the hidden layers, and Softmax is best used only in the output layer. Different network architectures, training data size, activation and cost functions, and batch sizes all require different learning rates and regularization strength to achieve good performance. See my next post, A Neural Network Program in Python: Part 2 for some examples.
I hope that you’ve enjoyed this post and found it useful. If you have any feedback please send me an email at contact@learningmachinelearning.org

Pingback: A Neural Network Program in Python: Part II | Learning Machine Learning